PDF Data Extractor Enterprise 3.06 | Portable
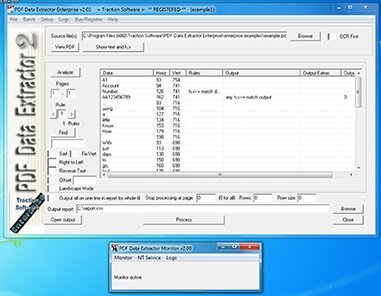
Only take match when Account Number: text is on the same page. Different fields can also be merged into one, so say First Name and Surname can be output as one field in the CSV file. Many options are available: Data Extraction, OCR pdf option, OCR number correction, Adjust for Skewed pdf page option, Full Unicode support for other language files e.g. Hebrew, Right to Left reading order option, Offset on a word on the page for dealing with Chopped Scanned PDF's, Number, Date & Money / Date / Address / Email / Telephone Number / Number filtering, Smart Adobe Reader PDF Highlight Setup, Output filename using data, Pattern Matching, Data file lookup for matching codes for descriptions, Data column order assignment, Run on the command line, Header output, page number field, filename field, Batch list of files to process, 32bit and 64bit versions.
Also can now rename or copy files to a new location based on data extracted.
Enterprise version also supports: Hot Folder Multi-Threaded Monitoring, NT Service background support, SQL Server database insert support for updating a database directly from pdf data and other DOS Commands per data extracted for full enterprise flexibility.
Stand Alone version (Does NOT require Adobe Acrobat)
32bit and 64bit versions for faster processing
Unicode support for all languages e.g. English, Japanese, Chinese, Hebrew in the filename and in the text
Extract data from multiple page pdf's
Multiple output fields from the source pdf, by text before, positions, first match and last match downward and upward matching options.
Conditional matching rules system
Output fields such as: Total pages, page number matched, filename
Smart Highlight Setup feature: Highlight Data to extract in PDF using Adobe Reader, then Data Extractor imports this setup directly from the pdf
Output filename using data match in pdf e.g. c:\report_[COL1].csv
Data Formatting options, change to upper / lower / address detection / telephone number search / email data searching / date formats and more
Pattern matching options e.g. nn nnn nnn for numbers in format e.g. 12 345 678, aannn for alpha then numeric. e.g. AB123
Data lookup option for codes e.g. match code 123, then pull data from text list e.g. 123,Canon Printer will output Canon Printer
Quick smart header option one click button, analyzes data to create data header for you
Column output position option
OCR pdf first option
Date / Money / Alpha / Numeric output filtering
Copy text to clipboard option for putting into other software
Offset position start for dealing with scanned pdf's that for example have the header cut off or skewed, so all the positions can be calculated from a certain stable text point
Fix vertical text option for slightly skewed scans positions rounding to the nearest 5 points
Reverse text option for backwards mirrored scans
Right to Left word option support for languages like Hebrew
Process batch list of pdf's with Batch list processing
Optionally run on the command line for automation
Rename or copy files to a new location based on data extracted
Supports all pdf types except encrypted and protected.
Automatically saves settings for later use
Full logging of files processed, errors & moved.
Installer
Full HTML & PDF Help
Homepage | What's New
OS: Windows 7 / 8 / 8.1 / 10 / 11 / Server 2003 / 2008 / 2012 / 2016 / 2019 / 2022 (x86-x64)
Language: ML / ENG
Medicine: RegFile
Size: 1,53 MB.
Download From Homepage
Installer | Installer x64
No comments